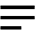
Available online 12 May 2025 (click here)
Abstract: Given the remarkable comprehensive ability, Large Language Models (LLMs) offer a promising solution for automatic geotechnical design. However, addressing multimodal geotechnical design assignments involving both text and image is still challenging for existing LLMs. This paper develops a framework integrating multiple LLMs, the multi-GeoLLM, for multi-modal geotechnical design. It can understand multimodal data, extract design information, and generate design solutions. The innovations involve four aspects: a search engine for multimodal geo-prompt generation; a multiple agent-based self-review module extracting design information; a tool module for decision-making, math calculation and drawing; and a Human-in-the-Loop Feedback (HLF) module for artificial review. Experiments involving 60 sets of text, image, and text-image data of unreinforced footings showcase the high performance of multi-GeoLLM with an accuracy of 1.0, precision and recall of 0.992. 100 textual cases also validated the robustness of multi-GeoLLM, achieving a precision of 0.999, a recall of 1 and an accuracy of 0.97.